本文翻译自 Anthropic 官方博客:Writing effective tools for AI agents—using AI agents
译者注:本文介绍了如何使用 AI Agent 来优化和改进工具设计的最佳实践。
模型上下文协议(MCP)可以为 LLM Agent 提供可能数百个工具来解决现实世界的任务。但是我们如何使这些工具最大限度地有效?
在本文中,我们描述了在各种 Agent AI 系统[1]中提高性能的最有效技术。
我们首先介绍如何:
- 构建和测试工具的原型
- 使用 Agent 创建和运行工具的综合评估
- 与 Claude Code 等 Agent 协作以自动提高工具性能
我们最后总结了我们在过程中发现的编写高质量工具的关键原则:
- 选择正确的工具来实现(和不实现)
- 使用命名空间定义功能中的清晰边界
- 从工具向 Agent 返回有意义的上下文
- 优化工具响应以提高 token 效率
- 提示工程工具描述和规范
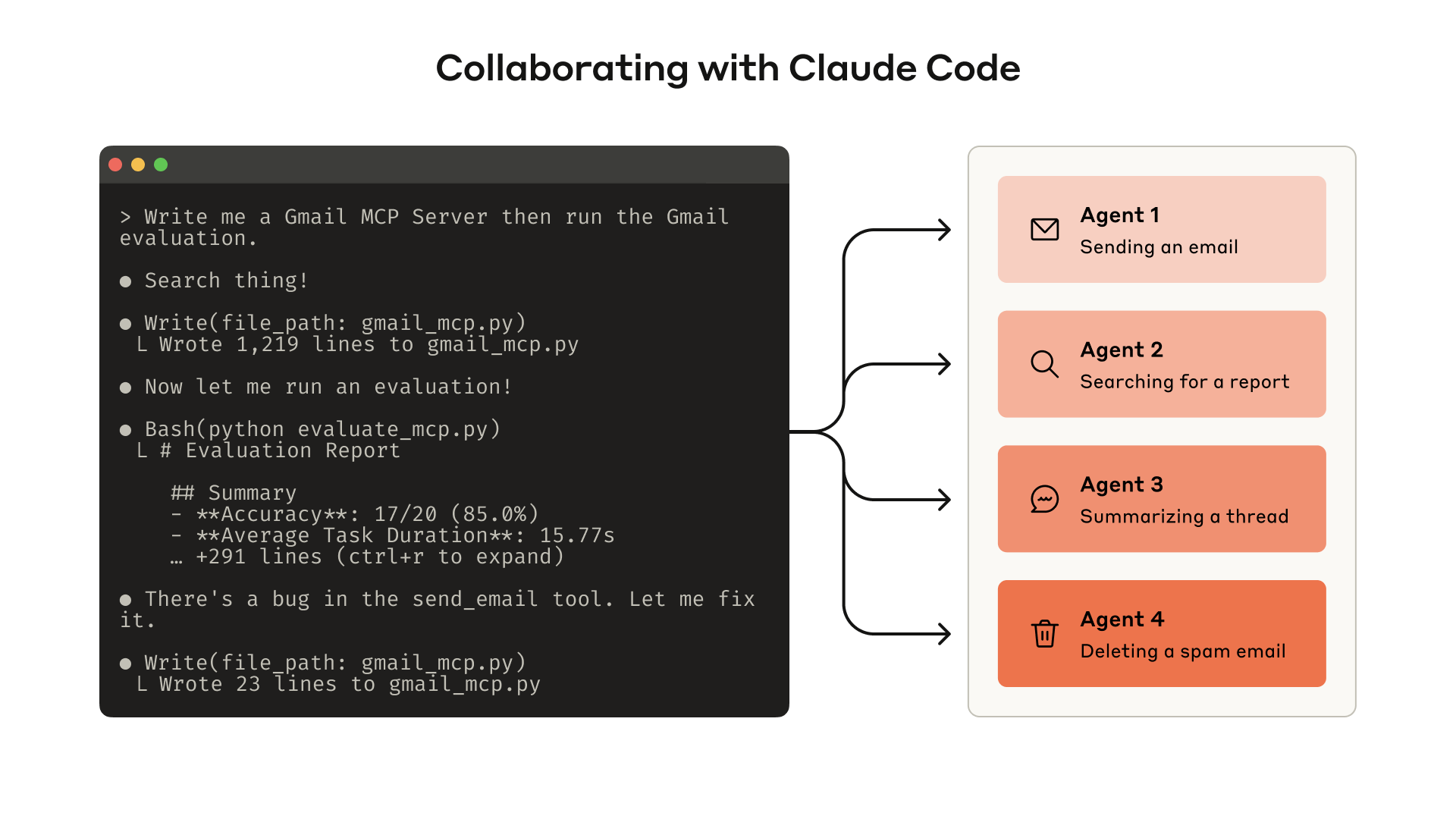
构建评估允许你系统地测量工具的性能。你可以使用 Claude Code 根据此评估自动优化你的工具。
什么是工具?
在计算中,确定性系统在给定相同输入的情况下每次都产生相同的输出,而非确定性系统——如 Agent——即使在相同起始条件下也可能生成不同的响应。
当我们传统地编写软件时,我们正在建立确定性系统之间的契约。例如,像 getWeather("NYC") 这样的函数调用每次调用时都会以完全相同的方式获取纽约市的天气。
工具是一种新型的软件,它反映了确定性系统与非确定性 Agent 之间的契约。当用户问"我今天应该带伞吗?"时,Agent 可能会调用天气工具、从一般知识中回答,或者甚至先询问一个关于位置的澄清问题。偶尔,Agent 可能会产生幻觉,甚至无法掌握如何使用工具。
这意味着在为 Agent 编写软件时需要从根本上重新思考我们的方法:我们需要为 Agent 设计工具和 MCP 服务器,而不是像为其他开发者或系统编写函数和 API 那样。
我们的目标是通过使用工具来追求各种成功策略,增加 Agent 可以有效解决广泛任务的表面积。幸运的是,根据我们的经验,对 Agent 来说最"人体工程学"的工具最终对人类来说也出奇地直观。
如何编写工具
在本节中,我们将描述如何与 Agent 协作来编写和改进你给它们的工具。首先快速构建工具的原型并在本地测试它们。接下来,运行综合评估以测量后续更改。与 Agent 一起,你可以重复评估和改进工具的过程,直到你的 Agent 在现实世界的任务上实现强大的性能。
构建原型
如果不亲自动手,很难预料 Agent 会觉得哪些工具符合人体工程学,哪些不会。首先快速构建工具的原型。如果你使用 Claude Code 编写工具(可能是一次性),给 Claude 提供你的工具将依赖的任何软件库、API 或 SDK(可能包括 MCP SDK)的文档会有所帮助。LLM 友好的文档通常可以在官方文档站点上的平面 llms.txt 文件中找到(这是我们的 API 的)。
将你的工具包装在本地 MCP 服务器或桌面扩展(DXT)中将允许你在 Claude Code 或 Claude Desktop 应用中连接和测试你的工具。
要将本地 MCP 服务器连接到 Claude Code,请运行 claude mcp add <name> <command> [args...]。
要将本地 MCP 服务器或 DXT 连接到 Claude Desktop 应用,请分别导航到 Settings > Developer 或 Settings > Extensions。
工具也可以直接传递到 Anthropic API 调用中以进行程序化测试。
自己测试工具以识别任何粗糙的边缘。从你的用户那里收集反馈,以围绕你期望工具实现的用例和提示建立直觉。
运行评估
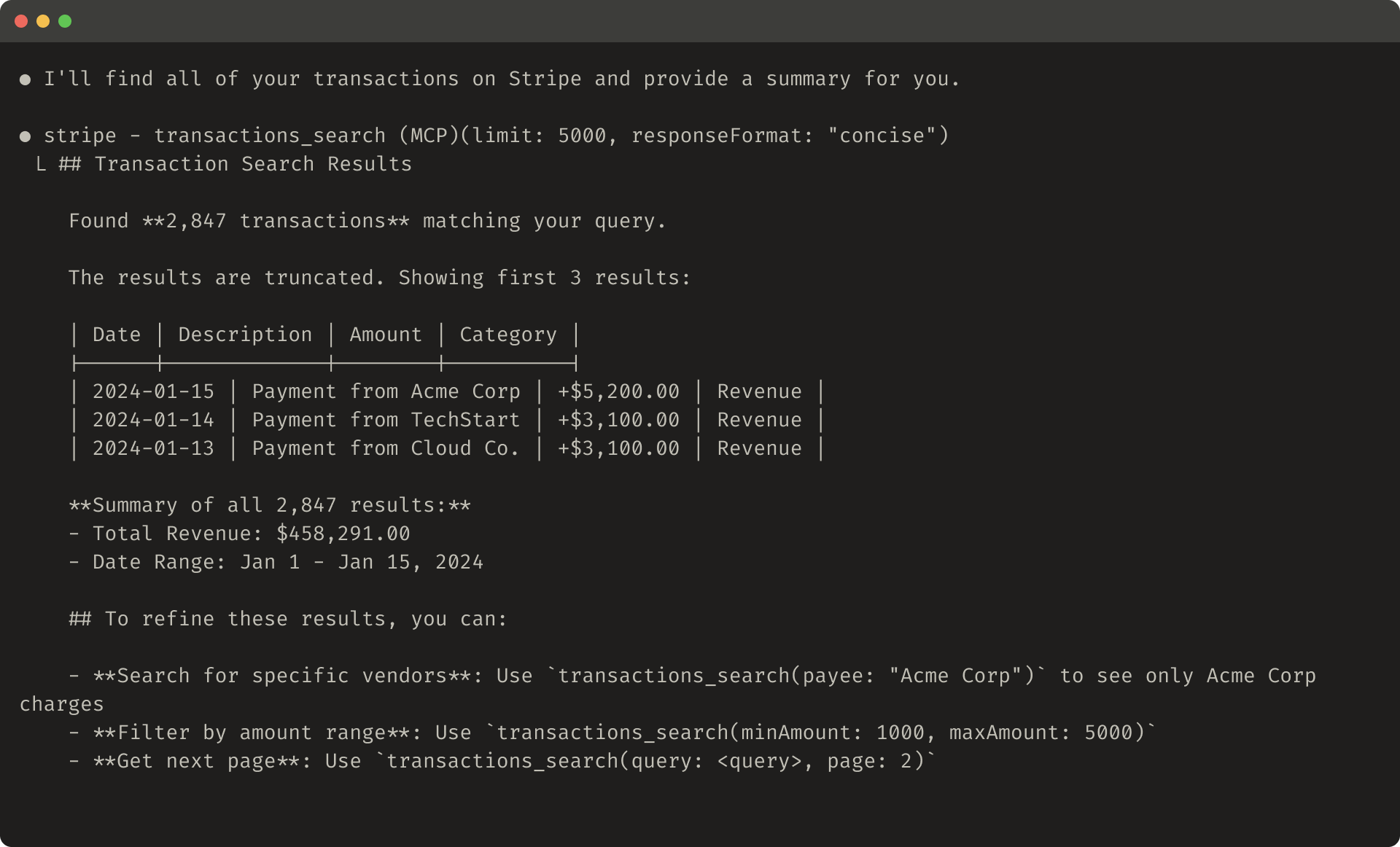
接下来,你需要通过运行评估来测量 Claude 使用你的工具的效果。首先生成大量评估任务,基于现实世界的使用。我们建议与 Agent 合作帮助分析你的结果并确定如何改进你的工具。在我们的工具评估 cookbook 中端到端地看到此过程。
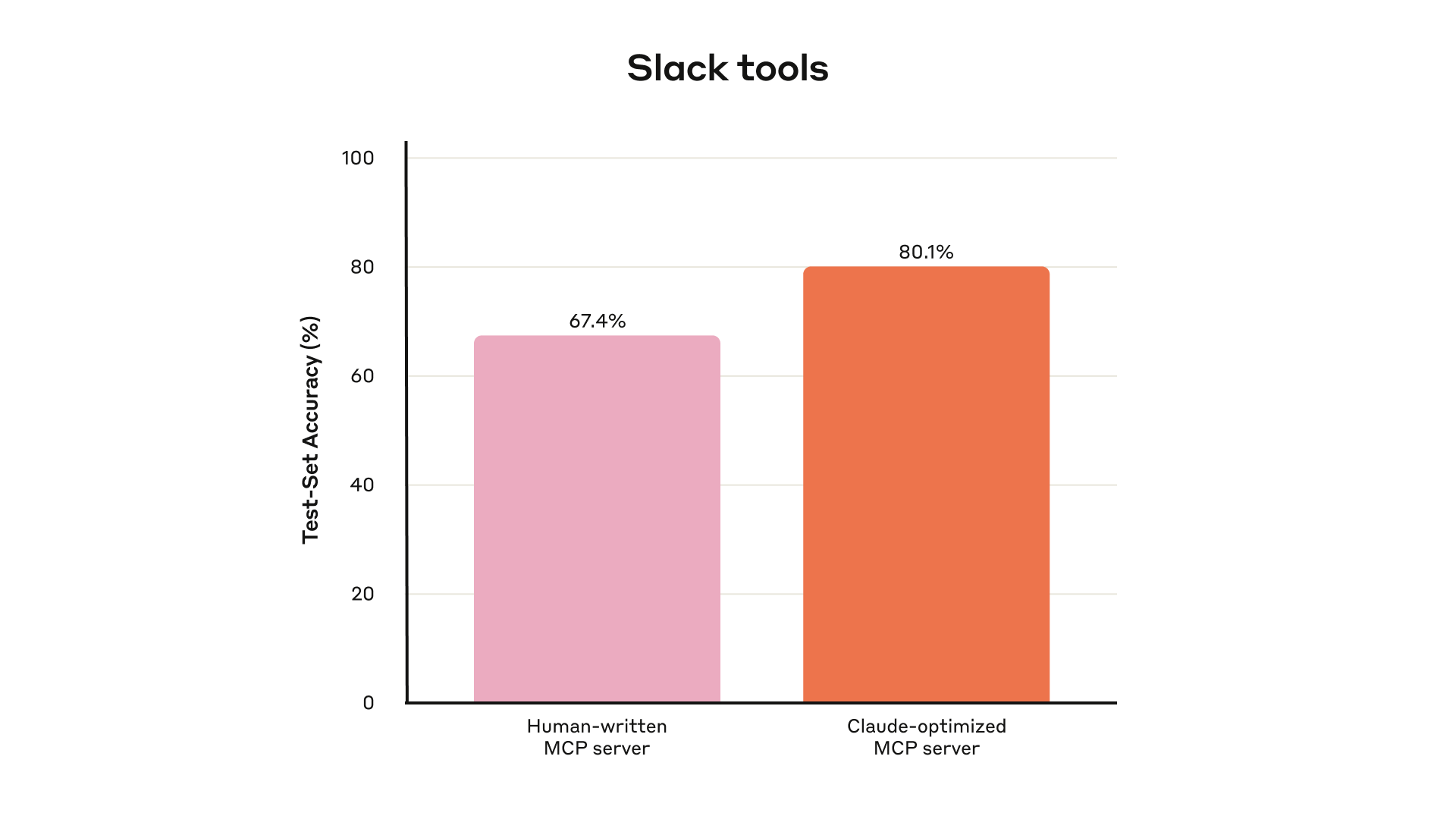
我们的内部 Slack 工具的保留测试集性能
生成评估任务
使用你的早期原型,Claude Code 可以快速探索你的工具并创建几十个提示和响应对。提示应该受到现实世界使用的启发,并基于现实的数据源和服务(例如,内部知识库和微服务)。我们建议你避免过于简单或肤浅的"沙箱"环境,这些环境不会以足够的复杂性压力测试你的工具。强大的评估任务可能需要多次工具调用——可能是几十次。
以下是一些强大任务的示例:
- 与 Jane 安排下周的会议讨论我们最新的 Acme Corp 项目。附加我们上次项目规划会议的笔记并预留会议室。
- 客户 ID 9182 报告说他们被收取了三次单次购买尝试的费用。查找所有相关的日志条目并确定是否有任何其他客户受到同一问题的影响。
- 客户 Sarah Chen 刚刚提交了取消请求。准备保留报价。确定:(1)他们离开的原因,(2)什么保留报价最有说服力,以及(3)在提供报价之前我们应该意识到的任何风险因素。
以下是一些较弱的任务:
- 与 jane@acme.corp 安排下周的会议。
- 在支付日志中搜索
purchase_complete和customer_id=9182。 - 查找客户 ID 45892 的取消请求。
每个评估提示都应该配有一个可验证的响应或结果。你的验证器可以简单到基本事实和采样响应之间的精确字符串比较,也可以高级到让 Claude 判断响应。避免过于严格的验证器,这些验证器由于虚假的差异(如格式、标点符号或有效的替代措辞)而拒绝正确的响应。
对于每个提示-响应对,你还可以选择指定你期望 Agent 在解决任务时调用的工具,以测量 Agent 是否在评估期间成功掌握每个工具的目的。然而,由于可能有多种有效路径可以正确解决任务,因此尽量避免过度指定或过度拟合策略。
运行评估
我们建议通过直接 LLM API 调用以编程方式运行你的评估。使用简单的 Agent 循环(包装交替 LLM API 和工具调用的 while 循环):每个评估任务一个循环。每个评估 Agent 应该被赋予单个任务提示和你的工具。
在评估 Agent 的系统提示中,我们建议指示 Agent 不仅输出结构化响应块(用于验证),还输出推理和反馈块。指示 Agent 在工具调用和响应块之前输出这些可能会通过触发思维链(CoT)行为来增加 LLM 的有效智能。
如果你使用 Claude 运行评估,你可以打开交错思考以获得类似的"现成"功能。这将帮助你探测为什么 Agent 调用或不调用某些工具,并突出工具描述和规范中需要改进的特定领域。
除了顶级准确性,我们还建议收集其他指标,例如单个工具调用和任务的总运行时间、工具调用的总数、总 token 消耗和工具错误。跟踪工具调用可以帮助揭示 Agent 追求的常见工作流程,并提供一些工具合并的机会。

我们的内部 Asana 工具的保留测试集性能
分析结果
Agent 是你在发现问题方面有用的合作伙伴,并提供从矛盾的工具描述到低效的工具实现和混乱的工具模式等所有内容的反馈。然而,请记住 Agent 在反馈和响应中省略的内容往往比它们包含的内容更重要。LLM 并不总是说他们的意思。
观察你的 Agent 被困住或困惑的地方。通读你的评估 Agent 的推理和反馈(或 CoT)以识别粗糙的边缘。查看原始记录(包括工具调用和工具响应)以捕获任何未在 Agent 的 CoT 中明确描述的行为。解读字里行间;记住你的评估 Agent 不一定知道正确的答案和策略。
分析你的工具调用指标。大量冗余的工具调用可能表明需要对分页或 token 限制参数进行一些合理的调整;大量无效参数的工具错误可能表明工具需要更清晰的描述或更好的示例。当我们启动 Claude 的网络搜索工具时,我们发现 Claude 不必要地将 2025 附加到工具的 query 参数,偏颇了搜索结果并降低了性能(我们通过改进工具描述将 Claude 引导到正确的方向)。
与 Agent 协作
你甚至可以让 Agent 分析你的结果并为你改进工具。只需连接你的评估 Agent 的记录并将它们粘贴到 Claude Code 中。Claude 是分析记录和一次重构大量工具的专家——例如,以确保在进行新更改时工具实现和描述保持自洽。
事实上,本文中的大多数建议来自反复使用 Claude Code 优化我们的内部工具实现。我们的评估是在我们的内部工作空间之上创建的,反映了我们内部工作流的复杂性,包括真实的项目、文档和消息。
我们依赖保留测试集以确保我们不会过度拟合我们的"训练"评估。这些测试集显示,我们可以提取额外的性能改进,甚至超出我们用"专家"工具实现所达到的——无论这些工具是由我们的研究人员手动编写还是由 Claude 本身生成。
在下一节中,我们将分享我们从这个过程中学到的一些东西。
编写有效工具的原则
在本节中,我们将我们的学习提炼为编写有效工具的一些指导原则。
为 Agent 选择正确的工具
更多的工具并不总是导致更好的结果。我们观察到的一个常见错误是工具仅仅包装现有的软件功能或 API 端点——无论这些工具是否适合 Agent。这是因为 Agent 具有与传统软件不同的"功能可供性"(affordances)——也就是说,它们对使用这些工具的潜在行动有不同的感知方式
LLM Agent 具有有限的"上下文"(即,它们可以一次处理的信息量有限制),而计算机内存便宜且丰富。考虑在地址簿中搜索联系人的任务。传统软件程序可以有效地存储和处理联系人列表,一次一个,在继续之前检查每个联系人。
然而,如果 LLM Agent 使用返回所有联系人的工具然后必须逐个 token 地读取每个联系人,它会在无关信息上浪费有限的上下文空间(想象通过从上到下读取每一页来搜索地址簿中的联系人——即,通过蛮力搜索)。更好和更自然的方法(对 Agent 和人类 alike)是首先跳转到相关页面(也许按字母顺序找到它)。在地址簿案例中,你可能会选择实现 search_contacts 或 message_contact 工具而不是 list_contacts 工具。
工具可以整合功能,在底层处理潜在的多个离散操作(或 API 调用)。例如,工具可以使用相关元数据丰富工具响应,或者在单个工具调用中处理经常链接的多步骤任务。
以下是一些示例:
- 不要实现
list_users、list_events和create_event工具,考虑实现schedule_event工具,它可以找到可用性并安排事件。 - 不要实现
read_logs工具,考虑实现search_logs工具,它只返回相关的日志行和一些周围的上下文。 - 不要实现
get_customer_by_id、list_transactions和list_notes工具,实现get_customer_context工具,它可以一次性编译客户的所有最近和相关信息。
确保你构建的每个工具都有清晰、独特的目的。工具应该允许 Agent 像人类一样细分和解决任务(如果可以访问相同的底层资源),同时减少否则会被中间输出消耗的上下文。
太多的工具或重叠的工具也会分散 Agent 对追求有效策略的注意力。仔细、有选择地规划你构建(或不构建)的工具确实可以带来回报。
为工具命名空间
你的 AI Agent 可能会获得访问数十个 MCP 服务器和数百个不同工具——包括其他开发者的工具。当工具在功能上重叠或目的模糊时,Agent 可能会对使用哪个工具感到困惑。
命名空间(将相关工具分组在公共前缀下)可以帮助描绘大量工具之间的边界;MCP 客户端有时默认会这样做。例如,按服务(例如,asana_search、jira_search)和按资源(例如,asana_projects_search、asana_users_search)为工具命名空间,可以帮助 Agent 在正确的时间选择正确的工具。
我们发现选择基于前缀和后缀的命名空间对我们的工具使用评估有非平凡的影响。效果因 LLM 而异,我们鼓励你根据自己的评估选择命名方案。
Agent 可能会调用错误的工具、使用错误的参数调用正确的工具、调用太少的工具或错误地处理工具响应。通过有选择地实现名称反映任务的天然细分的工具,你同时减少了加载到 Agent 上下文中的工具和工具描述的数量,并将 Agent 计算从 Agent 的上下文卸载回工具调用本身。这降低了 Agent 犯错的总体风险。
从工具返回有意义的上下文
同样,工具实现应该注意只向 Agent 返回高信号信息。它们应该优先考虑上下文相关性而不是灵活性,避免低级技术标识符(例如:uuid、256px_image_url、mime_type)。像 name、image_url 和 file_type 这样的字段更有可能直接告知 Agent 的下游行动和响应。
Agent 也倾向于更成功地处理自然语言名称、术语或标识符,而不是神秘的标识符。我们发现,仅将任意字母数字 UUID 解析为更具语义意义和可解释的语言(甚至是 0 索引的 ID 方案)可以显著提高 Claude 在检索任务中的准确性,通过减少幻觉。
在某些情况下,Agent 可能需要灵活地与自然语言和技术标识符输出交互,如果只是为了触发下游工具调用(例如,search_user(name='jane') → send_message(id=12345))。你可以通过在工具中公开简单的 response_format 枚举参数来启用两者,允许你的 Agent 控制工具是返回 "concise" 还是 "detailed" 响应(下图)。
你可以添加更多格式以获得更大的灵活性,类似于 GraphQL,你可以选择你想要接收的确切信息片段。以下是控制工具响应冗长度的示例 ResponseFormat 枚举:
enum ResponseFormat {
DETAILED = "detailed",
CONCISE = "concise"
}
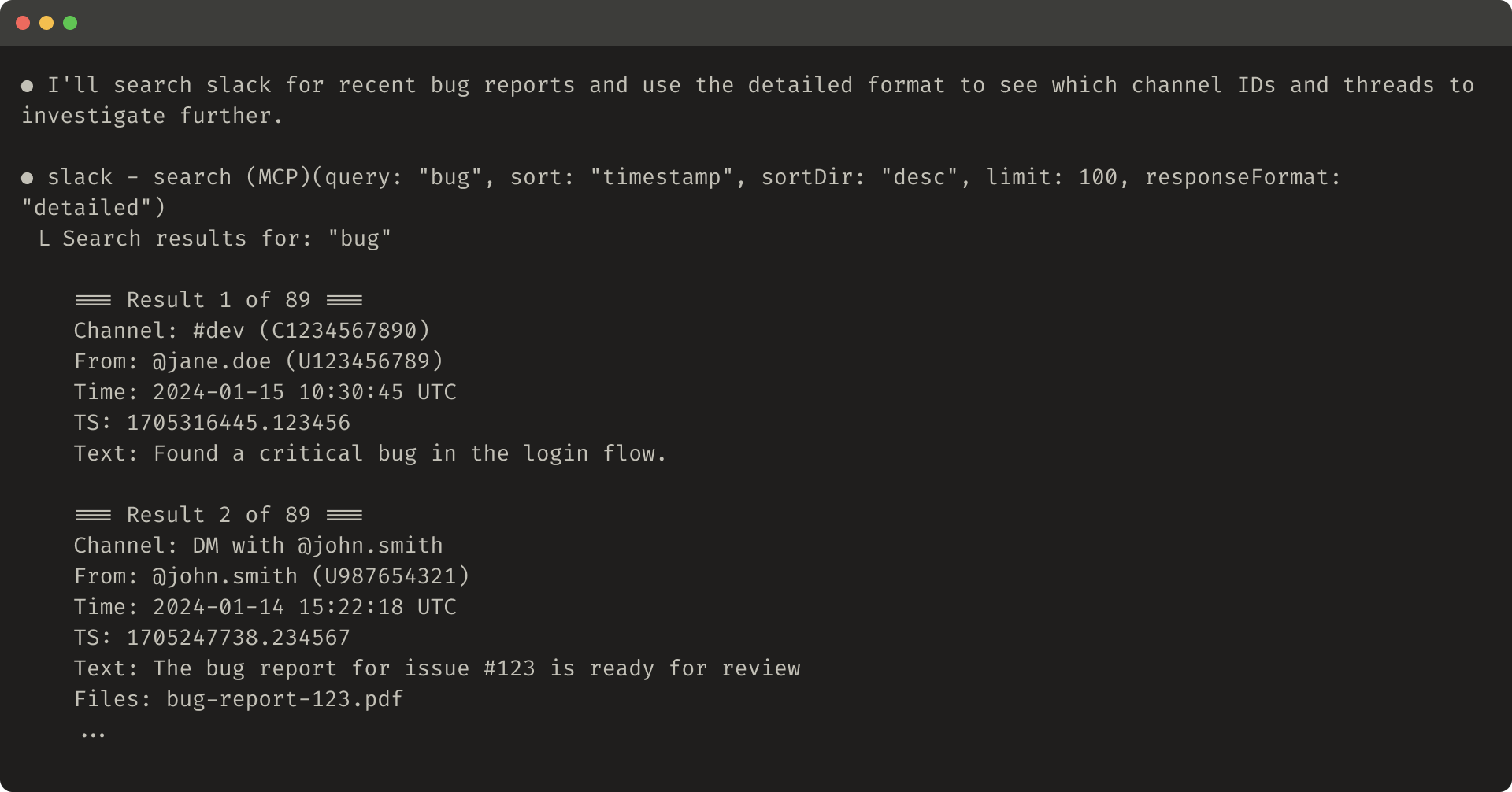
以下是详细工具响应的示例(206 token):
以下是简洁工具响应的示例(72 token):
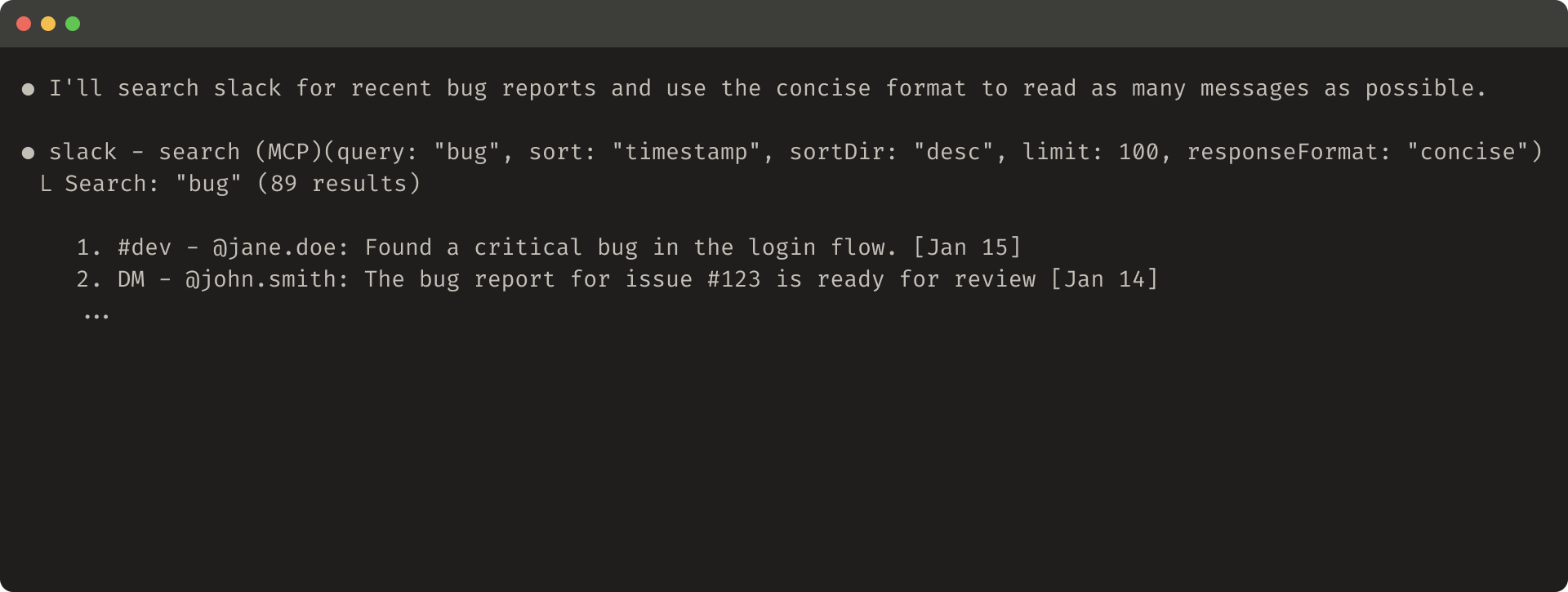
Slack 线程和线程回复由唯一的 thread_ts 标识,这是获取线程回复所需的。thread_ts 和其他 ID(channel_id、user_id)可以从 "detailed" 工具响应中检索,以启用需要这些的进一步工具调用。"concise" 工具响应只返回线程内容并排除 ID。在此示例中,我们使用 "concise" 工具响应的大约 ⅓ 的 token。
甚至你的工具响应结构——例如 XML、JSON 或 Markdown——也可能影响评估性能:没有一刀切的解决方案。这是因为 LLM 是在下一个 token 预测上训练的,并且在与训练数据匹配的格式上表现更好。最佳响应结构将因任务和 Agent 而异。我们鼓励你根据自己的评估选择最佳响应结构。
优化工具响应以提高 token 效率
优化上下文质量很重要。但是优化在工具响应中返回给 Agent 的上下文数量也很重要。
我们建议为任何可能使用大量上下文的工具响应实现一些分页、范围选择、过滤和/或截断的组合,以及合理的默认参数值。对于 Claude Code,我们默认将工具响应限制为 25,000 token。我们期望 Agent 的有效上下文长度会随着时间的推移而增长,但对上下文高效工具的需求仍然存在。
如果你选择截断响应,请确保通过有用的指令引导 Agent。你可以直接鼓励 Agent 追求更节省 token 的策略,例如,对于知识检索任务,进行许多小的和有针对性的搜索,而不是单一的、广泛的搜索。同样,如果工具调用引发错误(例如,在输入验证期间),你可以提示工程你的错误响应以清楚地传达具体的和可操作的改进,而不是不透明的错误代码或跟踪。
以下是截断工具响应的示例:
以下是无用错误响应的示例:
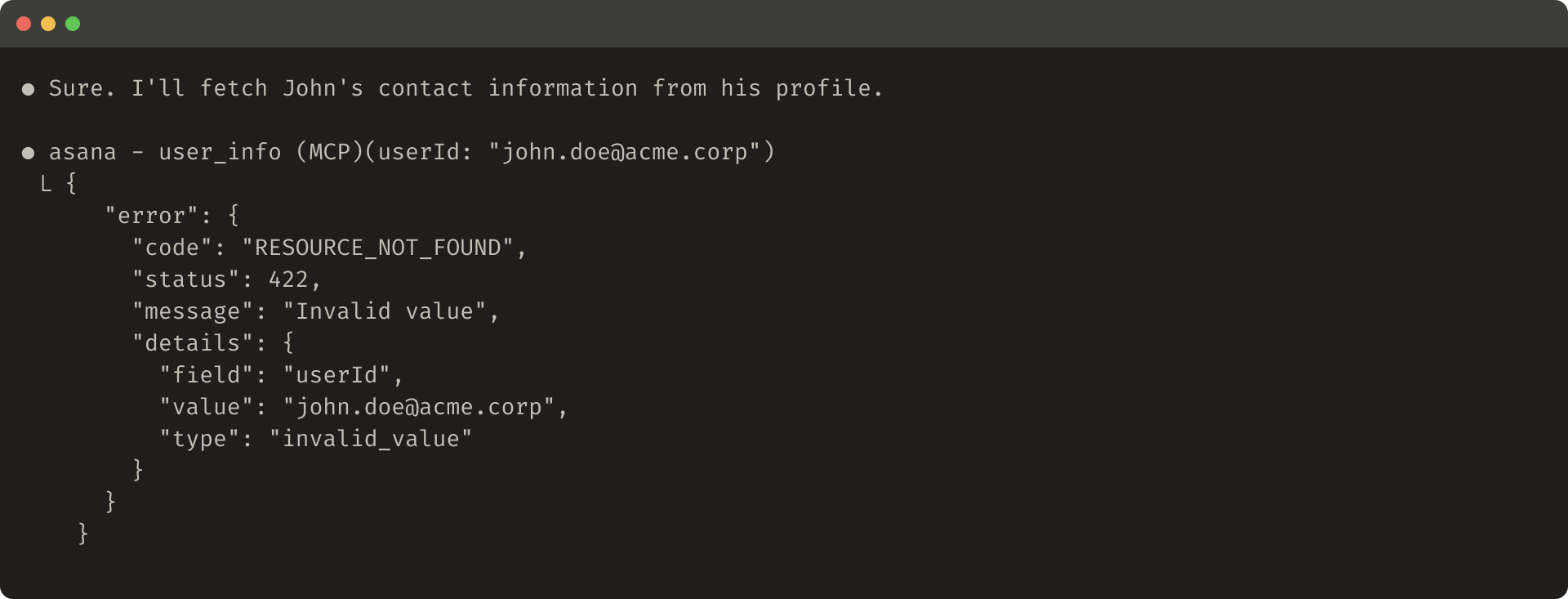
以下是有用错误响应的示例:

工具截断和错误响应可以引导 Agent 朝着更节省 token 的工具使用行为(使用过滤器或分页),或者给出正确格式的工具输入示例。
提示工程你的工具描述
我们现在来介绍改进工具的最有效方法之一:提示工程你的工具描述和规范。因为这些被加载到你的 Agent 的上下文中,它们可以共同引导 Agent 朝着有效的工具调用行为。
在编写工具描述和规范时,想想你会如何向团队的新员工描述你的工具。考虑你可能隐式带来的上下文——专门的查询格式、小众术语的定义、底层资源之间的关系——并将其明确化。通过清楚地描述(并使用严格的数据模型强制执行)预期的输入和输出来避免歧义。特别是,输入参数应该明确命名:不要使用名为 user 的参数,尝试使用名为 user_id 的参数。
通过你的评估,你可以更有信心地衡量你的提示工程的影响。即使对工具描述的小改进也能产生显著的改进。在对工具描述进行精确改进后,Claude Sonnet 3.5 在 SWE-bench Verified 评估上实现了最先进的性能,显著降低了错误率并提高了任务完成率。
你可以在我们的开发者指南中找到工具定义的其他最佳实践。如果你为 Claude 构建工具,我们还建议阅读工具如何动态加载到 Claude 的系统提示中。最后,如果你为 MCP 服务器编写工具,工具注释有助于披露哪些工具需要开放世界访问或进行破坏性更改。
展望未来
为了为 Agent 构建有效的工具,我们需要将我们的软件开发实践从可预测的、确定性的模式重新定位为非确定性的模式。
通过本文中描述的迭代、评估驱动的过程,我们已经确定了工具成功的一致模式:有效的工具是有意和清晰定义的,明智地使用 Agent 上下文,可以在多样化的工作流中组合在一起,并使 Agent 能够直观地解决现实世界的任务。
在未来,我们期望 Agent 与世界交互的具体机制会演变——从对 MCP 协议的更新到对底层 LLM 本身的升级。通过系统、评估驱动的方法改进 Agent 的工具,我们可以确保随着 Agent 变得更有能力,它们使用的工具将与它们一起演变。
致谢
由 Ken Aizawa 撰写,来自研究(Barry Zhang、Zachary Witten、Daniel Jiang、Sami Al-Sheikh、Matt Bell、Maggie Vo)、MCP(Theodora Chu、John Welsh、David Soria Parra、Adam Jones)、产品工程(Santiago Seira)、营销(Molly Vorwerck)、设计(Drew Roper)和应用 AI(Christian Ryan、Alexander Bricken)同事的宝贵贡献。
[1] 除了训练底层 LLM 本身。